Back in January 2020, when the world seemed a much more predictable place, I started publicly practising forecasting. Philip Tetlock’s great book, Superforecasting, emphasized how important it was to actually train one’s forecasting skills, so I had been wanting to get involved in making predictions for a couple years. I decided to pit myself against Vox’s Future Perfect team by making my own predictions based on their list of 19 predictions for 2020.
I also logged the predictions on forecasting platform Metaculus. I’ve since made other predictions on the platform and like to check in on the crowd’s wisdom for pandemic-related predictions.
I began working on my predictions the day after Vox posted their list (along with predictions) and finalised them a few days later on the 17th of January 2020. I think Bayesian reasoning is a useful tool, so I started by spending a few minutes considering each statement and assigning it with a prior probability (as a percentage). I then spent a few days deliberating and researching each statement. This process allowed me to update my prior predictions to posterior predictions. I logged both of these for each of the 19 statements.
Vox published an article reviewing their predictions in early January of 2021. This (and the resolutions on Metaculus) were my guide for evaluating my performance. At the time of Vox’s article, a few of the predictions hadn’t resolved yet, so I waited a while before doing my own analysis. I then waited a further couple of months before getting around to writing up this post.
Results
I’ve included both my prior and posterior predictions, along with Vox’s. The outcome is a binary value based on the Metaculus resolution. Note: I’ve logically inverted some of the predictions so that all the posterior probabilities are $\geq 50$.
df = pd.read_csv('preds2020.csv')
df
| Prediction | Prior | Posterior | Vox | Outcome |
|---|---|---|---|---|
| Donald Trump will win reelection | 0.70 | 0.55 | 0.55 | 0 |
| The Democratic nominee will be Joe Biden | 0.65 | 0.55 | 0.60 | 1 |
| The GOP holds the Senate | 0.75 | 0.65 | 0.80 | 1 |
| Trump will not get a new Supreme Court appoint… | 0.55 | 0.75 | 0.70 | 0 |
| The Supreme Court will allow more abortion res… | 0.55 | 0.65 | 0.90 | 0 |
| The Democratic primary will be settled on Supe… | 0.50 | 0.55 | 0.60 | 0 |
| The number of people in global poverty will fall | 0.75 | 0.70 | 0.60 | 0 |
| Brexit (finally) happens | 0.80 | 0.90 | 0.95 | 1 |
| The US does not invade and attempts a regime c… | 0.70 | 0.80 | 0.80 | 1 |
| China will fail to curtail its Uyghur/Muslim i… | 0.70 | 0.80 | 0.85 | 1 |
| Netanyahu will not be unseated as Israeli prim… | 0.70 | 0.55 | 0.55 | 1 |
| No gene drives to fight malaria-carrying mosqu… | 0.70 | 0.80 | 0.90 | 1 |
| No new CRISPR-edited babies will be born | 0.45 | 0.75 | 0.80 | 1 |
| The number of drug-resistant infections will i… | 0.75 | 0.85 | 0.70 | 1 |
| Facial recognition will be banned in at least … | 0.65 | 0.65 | 0.70 | 1 |
| Beyond Meat will outperform the general stock … | 0.40 | 0.55 | 0.70 | 1 |
| Global carbon emissions will increase | 0.70 | 0.85 | 0.80 | 0 |
| Average world temperatures will increase relat… | 0.60 | 0.55 | 0.60 | 1 |
| California has a wildfire among the 10 most de… | 0.45 | 0.58 | 0.60 | 1 |
Okay, let’s see how many of the 19 predictions Vox, my priors, and my posteriors got right.
print(f"VOX correct:\t\t{np.sum(np.abs(df.Outcome - df.Vox) < 0.5)}")
print(f"Priors correct:\t\t{np.sum(np.abs(df.Outcome - df.Prior) < 0.5)}")
print(f"Posteriors correct:\t{np.sum(np.abs(df.Outcome - df.Posterior) < 0.5)}")
VOX correct: 13
Priors correct: 10
Posteriors correct: 13
Okay, 68% accuracy isn’t too terrible. I also matched Vox. And my initial hunches (the priors) definitely seem to have been improved by a Bayesian update. But correctness isn’t a very useful scoring metric in forecasting, as it doesn’t take the confidence of the predictions into account.
To score the overall predictions, I used the Brier score, which is standard in forecasting. It’s essentially just the mean squared error over all predictions. We can use a simple version that only considers one prediction per statement, instead of a series of updates.
$$ \text{brier}=\frac{1}{N} \sum_{i=1}^{N}\left(f_{i}-o_{i}\right)^{2} $$where $f_i$ is forecast probability of statement $i$, $o_i$ is the outcome of statement $i$, and $N$ is the number of statements.
# Brier scores
print(f"VOX:\t\t{np.mean((df.Outcome - df.Vox)**2): .3f}")
print(f"Priors:\t\t{np.mean((df.Outcome - df.Prior)**2): .3f}")
print(f"Posteriors:\t{np.mean((df.Outcome - df.Posterior)**2): .3f}")
VOX: 0.214
Priors: 0.226
Posteriors: 0.224
So Vox had a lower forecasting error on average than I did, but only by a tiny bit. What’s most interesting to me is that my priors scored almost identically to my posteriors across all the predictions. The sample size is really too small to conclude anything from this, but it’s certainly interesting to note that the hours of research and deliberation I did made very little difference to the performance (on this occasion). This being despite the fact that my posteriors updated quite a bit from my priors. Let’s look at the distribution.
df.Prior.plot.kde(grid=False, label='Priors', alpha=0.6, linewidth='3', c='red')
df.Posterior.plot.kde(grid=False, label='Posteriors', alpha=0.6, linewidth='3', c='blue')
plt.axvline(df.Prior.mean(), linestyle='--', c='red')
plt.axvline(df.Posterior.mean(), linestyle='--', c='blue')
plt.xlabel('Prediction confidence')
plt.legend()
plt.show()
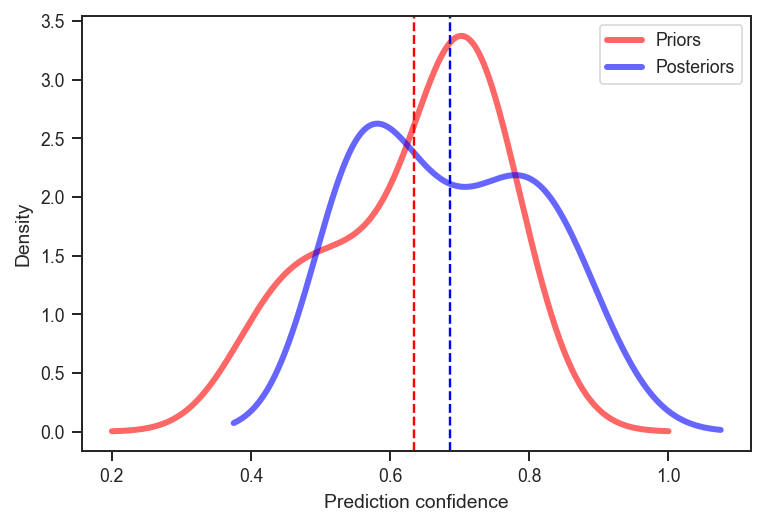
Those are notably different distributions. On average, my updates made me more confident about each statement. But, in the end, that didn’t amount to a significantly better performance. Again, the sample size here is small, so it wouldn’t be wise to generalise too much from this. But I’ll definitely be continuing to track both prior and posterior predictions in future.
One more piece of analysis. Let’s group all three sets of predictions by the outcome of the statement and look at the means.
df.boxplot(by='Outcome', column=['Prior', 'Posterior', 'Vox'], layout=(1,3))
plt.suptitle('')
plt.tight_layout()
plt.show()
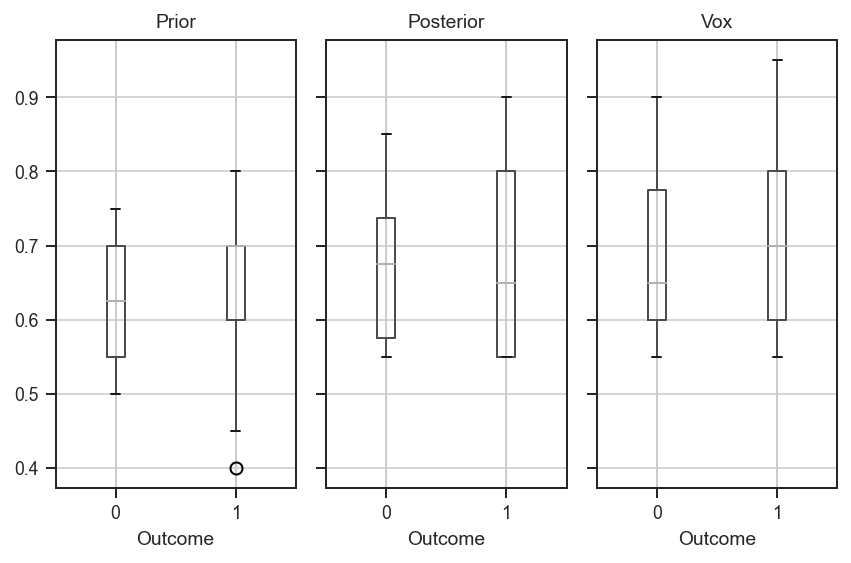
So we can see that, in general, when the statement did resolve as true, the predictions were slightly higher. But the priors have an interesting drooping whisker for the true outcomes. From this analysis, it seems like my posteriors were more informed, but may just have been informed by biased (or otherwise noisy) information. But I also seem to be less confident (both when I’m right and when I’m wrong) than Vox. Maybe I’m just more sensitive to tail risks, or maybe it has something to do with the journalism filter-bubble their team is in, or maybe it’s just artefacts of noisy data.
So, all things considered, I didn’t do too badly. Vox had 3 major advantages: (1) they’re a team of 3 people, so they form a natural ensemble, (2) they got to pick the questions, presumably in areas where they are informed, interested, and otherwise have good intuitions, and (3) they get paid to spend time researching and making these predictions. On the other hand, I had no choice but to see their predictions and (some of) their reasoning when I read the initial article — though I tried to avoid looking at any details or numbers until after I had made my prior predictions. If we’re honest, Vox as a media outlet messed up badly in 2020. But the Future Perfect team (especially Kelsey Piper) were the notable exception and seem to be genuinely interested in forecasting and being judged on their track record. I respect that.
Only 13 out of 19 correct, but I guess that’s what I get for starting my forey into global forecasting during the strangest year this century.