The Recurse Center (RC) hosts “Impossible Stuff Day” once per batch. It’s a whole day to spend working on something well beyond the edge of your abilities that feels totally impossible. The last one wasn’t productive for me, but I’m taking a different approach this time around.
UPDATE: I came back after taking a break to embed all the screenshots I took, write the metadata for this post, link to some things I didn’t find at the time, and do a light proofread. But the actual post was written in real time as I was building. I didn’t know where I would end up when I began.
16:00: I’m going to directly record my notes into this blog post as I go, with minimal filtering. I’m curious if that workflow will be helpful and fun compared to what I normally do — writing scrappy notes in Obsidian.
Idea dump
16:15: I have a running note with lists of goals, resources, and project ideas (big and small) to tackle during Recurse. I’m pulling out some that feel most interesting to me today and are most “impossible day” appropriate.
Big and impossible ideas
- Fine-tune and tweak local LLM for my workflows
- The AI coding assistant that makes you a better programmer
- LLM-enhanced news feed based on RSS from multiple sources, semantic filtering, summarisation, etc.
- Embedding-to-vision/3D models to make any data easy to explore as vibes. Worlds full of characters instead of charts and spreadsheets. The “Blindsight” thing.
- Figure out how to get large models running locally on MacBook, with acceleration.
- Make an audio-only game from scratch (in Rust?)
- Multimodal (vision + LLM) assistant for querying personal health data (e.g. HealthKit), spotting trends, making suggestions, etc. Ideally on-device.
Small and highly possible side quests
- Flesh out the functionality of tai (terminal AI) in Rust.
- Try getting flux.1 model running on Apple Silicon with
mps. See some issues on GH already. - Fork llm and just tailor it to myself. (If I keep the upstream stuff I can probably benefit from later improvements, whilst also optimising it for my own use cases.)
- Run whisper.cpp server locally, transcribe all Bit of a Tangent episodes (and make an LLM that RAGs / embeds them?)
- Try Mojo and use it to optimise something. TableDiffusion?
- OpenAI/GPT-based systems for automatically transcribing, organising, and actioning voicenotes I record on the go.
- Build my own version of Git Commit Message AI.
Picking a topic and scaling the scope to impossible
It’s 16:40, I’ve just finished the RC Zoom call for the Impossible Stuff Day kickoff, slammed a cup of coffee, and put the Social Network soundtrack on. You know the scene. Things are about to get built!
It’s 16:43 on a rainy Tuesday afternoon. I’m a little over-caffeinated, I’m not gonna lie. I need to do something to take my mind off things. Easy enough, except I need an idea…
A unifying theme in the brain dump above: running foundation models locally on my MacBook, fine-tuning/contextualising them with my data, integrating them into useful workflows, and then optimising for performance.
Doing all that in under 5 hours certainly feels ambitious, but not quite “impossible.”
16:48: One of the idea clusters I’ve been exploring in recent conversations has been focussed on the major limitation of frontier LLMs being that they’re trained to solve all the tasks in all the ways on all the data. The regression to the mean of human-created data on the internet + the entropy-minimising training regime means you get a bit of a midwit. Then you RLFH the capabilities away to make the model “safer” and more of a “friendly, helpful assistant.” Throw in some borderline-unethical human annotations coming from niche populations in developing nations and you get something that doesn’t feel quite as useful to me.
But what if that’s just a skill issue on my part? What if I should just be rolling my own bespoke assistant? Can I offset the value of scale by personalising and contextualising?
16:54: Adding in that exploratory goal (which will require “delving” into the weeds of LoRA, MoE, Metal/MPS, Llama, etc.) certainly upgrades the ambitious idea to a near-impossible one.
We’ve calibrated the scope. Let’s clarify what I’m actually trying to do here. What would outright victory entail?
The impossible target
A capable multi-modal LLM of at least 1B parameters running on my M2 MacBook (with GPU/ANE acceleration), fine-tuned/RLHFed to behave according to my preferences and goals, with my personal data, previous work, and current projects as context. And it would be running from a powerful and modular command line interface that supports UNIXy workflows (piping to stdin and from stdout, CL arguments, config dotfile, Vim integration).
Subgoals
17:10: Let’s break that down into chunks:
- (1) A capable multi-modal LLM of at least 1B parameters running on my M2 MacBook
- (1a) GPU/ANE acceleration
- (1b) Fine-tuned/RLHFed to behave according to my preferences and goals
- (2) My personal data, previous work, and current projects as context
- (3) Running from a powerful and modular command line interface that supports UNIXy workflows
- piping to stdin and from stdout, CL arguments, config dotfile, Vim integration, etc.
Tactics for achieving the impossible
17:15: Okay, that’s nice structure. What makes this achievable in a short timeframe? This has to be hackathon rules. I’m obviously doing this to learn and develop skills/experience, but writing boilerplate and scouring library docs is a waste of time and attention until I’ve validated an approach.
When I encounter that, LLMs seem like the right lever to apply: codegen the boilerplate with Supermaven/Cursor, ask o1-preview for recommendations and reviews.
Moreover, forking/incorporating existing open-source code is probably going to help me here. But I’m going to do it in the most modular way possible. That way, once I’ve validated that something works as desired as a black box, I can hot-swap it with my own version (or at least make a note to return later to dig deeper and roll my own).
It’s also my biannual occasion to give Cursor another try, so let me install that and add an API key.
17:22: In the meanwhile, I’m going to feed this entire post so far into o1-preview and have it give me some tips and suggestions.
Pairing with o1-preview
llm --model o1-preview "I'm an ML engineer who is highly capable at Python (Pandas, PyTorch, NumPy), moderately skilled at JavaScript and Bash, and about 20h into learning Rust. I understand Transformers and use LLMs daily. I mainly work in the terminal (bash, neovim, grep, etc.) on my M2 MacBook Pro. What follows is my plan for Impossible Day. Your task is to review the plan, help mebreak it down into smaller tasks, and advise me on what techniques and technologies best enable me to tackle this problem in a few hours:\n`cat ~/2-Areas/Blog/content/posts/rc-impossible-day-oct24/index.md`" | tee ~/0-Inbox/impossible-o1-$(ecdt).md
That gives this post to o1-preview via the llm CLI app, then tee both prints the response to stdout and writes it to a file. The ecdt call is a custom alias I wrote to “echo current date time”. It’s handy for ensuring unique file names and having timestamps to refer back to later.
17:40: o1-preview had great structure in the response, breaking my subgoals down further. Having lots of good keywording in this post probably helped. The context about me, my skills, and my hardware also seemed to guide it to more specific recommendations.
Useful tips it gave:
- Leverage Apple’s Metal Performance Shaders (MPS) for GPU acceleration in PyTorch.
- Explore tools like
llama.cpporggmlwhich offer optimized performance on Apple Silicon. - Utilize libraries like
peft(Parameter-Efficient Fine-Tuning) in PyTorch. - CLI Frameworks:
- Use
argparseorclickin Python for command-line argument parsing. - For Rust, consider
claporstructopt.
- Use
- Use Vim’s
system()function to send and receive data from your CLI application.
Most of the rest of its response was just re-wording what I’ve already written above in a more structured format combined with kinda banal suggestions like “regularly test each component as you develop to catch issues early.” Gee thanks.
Setting up Cursor
17:54: Installed Cursor. Major improvements to the setup and onboarding flow since I last used it. It allowed me to enable Vim keybinds and privacy mode off the bat, but then squandered that by forcing me to log in (which meant I had to go create and verify an account) only for me to then give it my own OpenAI API key anwyay. Also their defensibility and value-add is largely from their own custom models, which I will have limited/no access to. I also had to manually add o1-preview and o1-mini as viable models. Still not sure if this will work. And god damn there are so many annoying poppup things and calls-to-action and I want to run away back to my cozy neovim setup already…
18:10: I’ve just been on a whole tangent in Cursor trying to get it to help me modify my Hugo blog setup so that my code snippets have line wrapping, as it’s something that’s been bugging me and I figured this is a good test for Cursor. So far I’m not hugely impressed. It’s done a lot of bullshitting in the chat window and made bad recommendations. But the inline completion stuff was pretty good, especially once I was in the process of making the change. After I created a new .css file, it then knew what code to add to it (based on its suggestion) and then when I navigated to the header partial it knew to complete the linking to that new .css file. Of course, it didn’t actually achieve the desired result.
I then tried to ask it again using o1-preview, which I was surprised worked as I had just added that manually as a model option.
18:18: Great… now I’m back in the same feedback loop of LLMs suggesting code, the code causing an error, pasting the error back, the LLM re-writing the code, a new error, etc. This isn’t a better workflow…
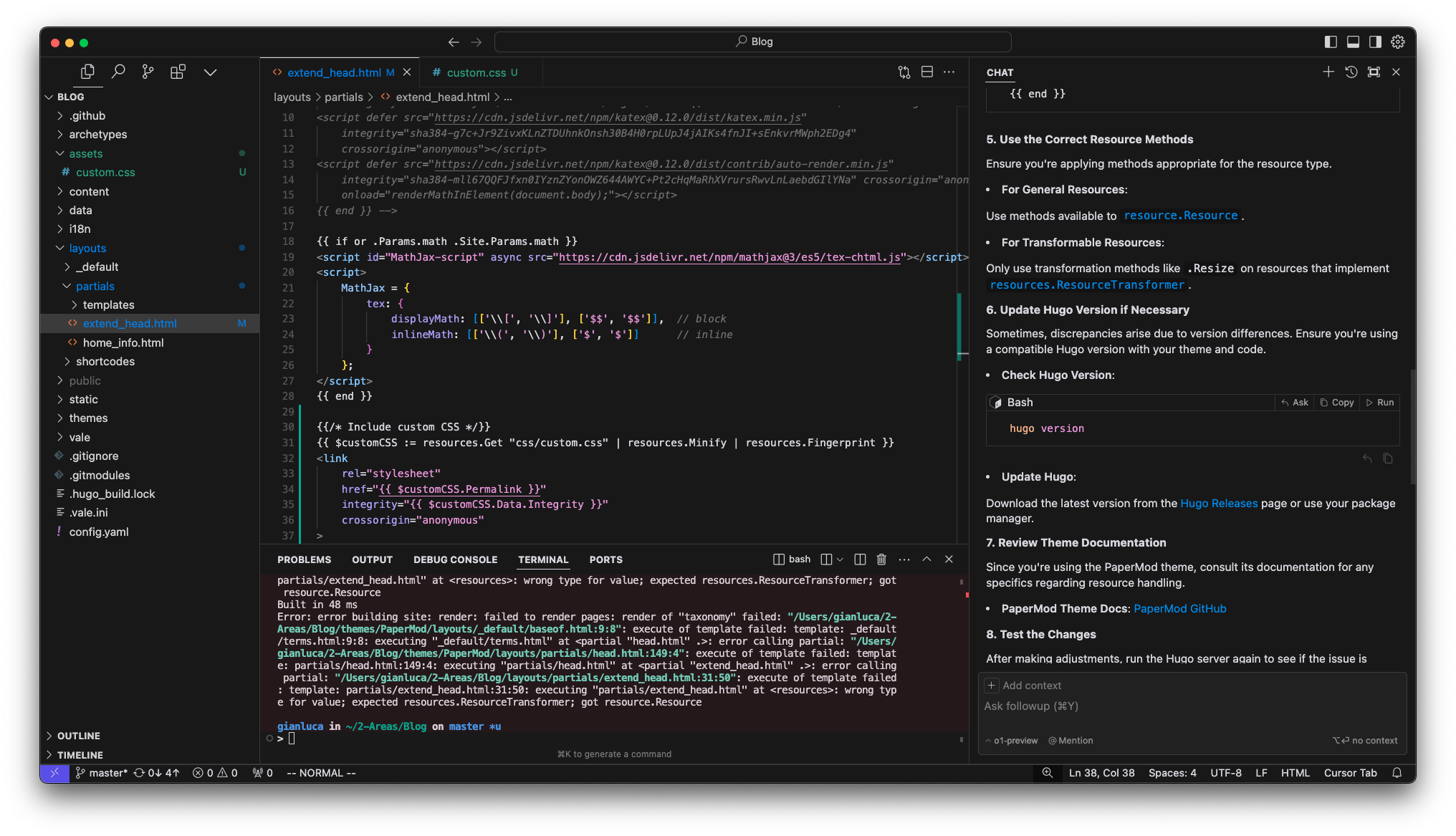
18:23: Dogshit! Wasted nearly an hour on this crap. git restore . and moving on…
A capable multi-modal LLM of at least 1B parameters running on my M2 MacBook
18:25: Okay, the first part to tackle is finding a suitable base LLM (preferably multimodal) that I can run locally. I think there was a new Llama release last week that has multiple model sizes and multimodal support. There are some asterisks around licensing, but “we busy building rn can’t be bothered with legal.”
18:31: Firstly, Meta’s llama webpage is so full of scripts and Facebook trackers that my hardened browser literally just rendered a blank page. We live in an enshittified hellscape. I’ll throw it into my sacrificial Chromium instance to progress.
Llama 3.2 is a collection of large language models (LLMs) pretrained and fine-tuned in 1B and 3B sizes that are multilingual text only, and 11B and 90B sizes that take both text and image inputs and output text.
Okay, based on some things I read recently and a few Fermi estimates, I believe you need about 2x the parameter count worth of memory for LLM inference (so call it 7GB for the 3B model and 25GB for the 11B model) and 4x for training. Obviously it’s less for finetuning with adaptors as you don’t need to keep a full set of gradients, but I’ll use that as an upper bound heuristic.
My over-specced-indulgence of a MacBook has 96GB of unified memory (shared between the GPU and CPU cores) and at least half of that sits idle when I’m writing prose, coding simple things, or just browsing. So I can probably get away with using the 11B model comfortably. But is multimodal support worth waiting on the download and the added complexity under my time constraints today? I dunno, but I can always fall back to the 3B text-only model.
18:41: Fuck you, Meta! I have to give you my personal information to download your “open” weights? Piss off! I can’t believe you’re doing this after I channeled 2003 Zuck energy earlier!
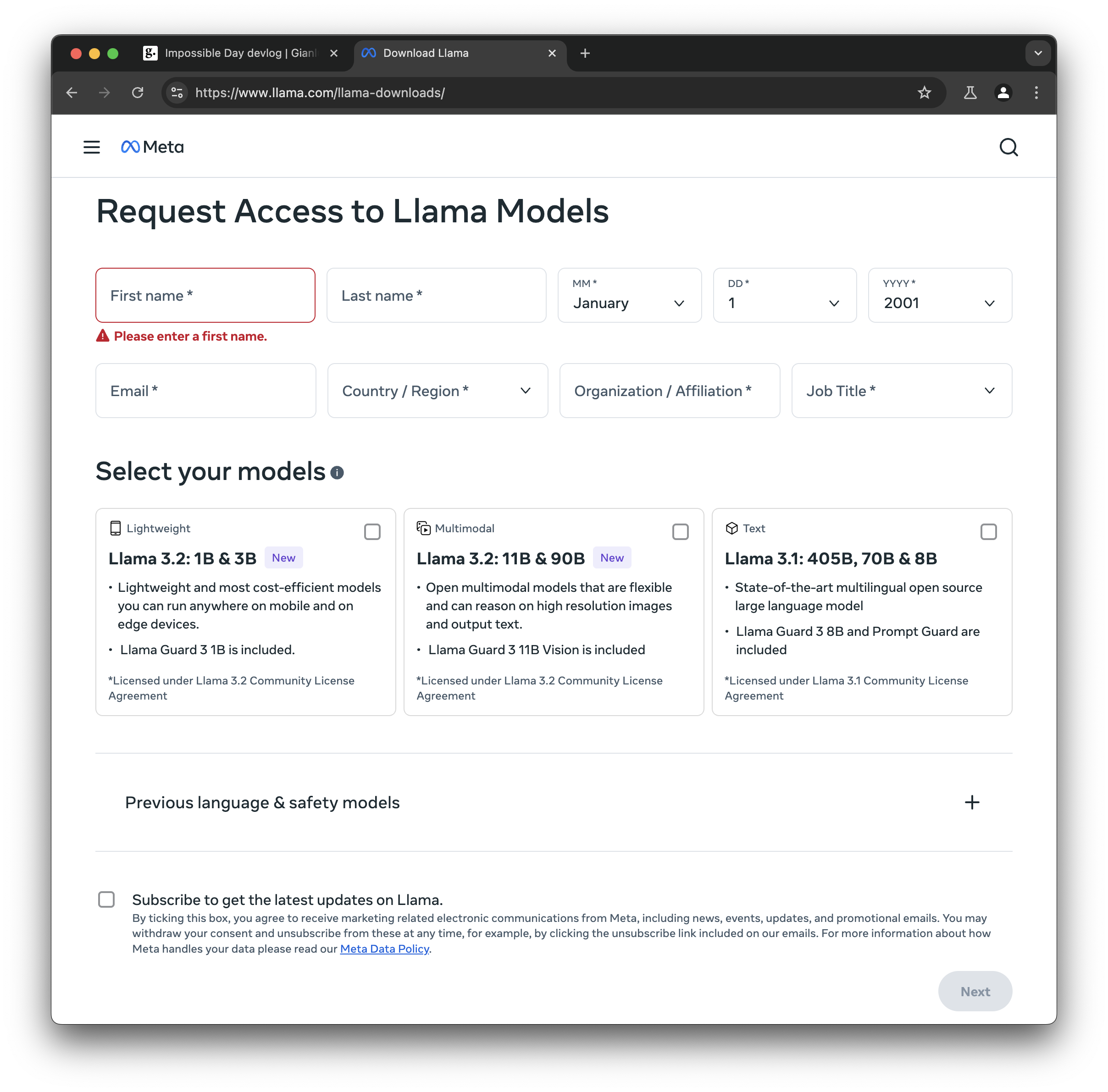
18:46: It seems like I can download the model from Huggingface, but I’ll still have to log in and “agree to share your contact information to access this model.” Hawk tuah!
But I’ll likely want to use HF’s transformers package to work with the model in Python/PyTorch for this project, so I guess that’s the lesser of evils. Plus the HF repo has more info about the models (context length 128k, knowledge cutoff Dec 2023, etc.) on those model cards.
JFC even when logged in it’s the same form!!! Why do you need my full date of birth Meta!?!?!
18:51: “Your country and region (based on approximate Internet address) will be shared with the model owner.” Honestly, I should have known better. So now I’m searching for alternatives on Hugginface.
18:58: Molmo 7B-D seems like it might fit the bill. 8B parameters, vision-text-to-text. Let’s see.
Setting up a project
uv init llmpossible
cd llmpossible
uv add einops torch torchvision transformers
And let’s make sure mps will work:
> uv run python
Python 3.10.14 (main, Aug 14 2024, 05:14:46) [Clang 18.1.8 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> torch.backends.mps.is_available()
True
>>> torch.backends.mps.is_built()
True
19:08: Running short on time. Who knew that the “impossible” part of Impossible Day was due to spending ages fighting with annoying signups and trying to defend my right to privacy.
Let’s use the recommended Python boilerplate on Molmo’s Huggingface repo to get the weights downloading, then I’ll probably need to update it to use mps backend instead of cuda. It may not even work.
19:14: No dice. It fails early:
ImportError: Using `low_cpu_mem_usage=True` or a `device_map` requires Accelerate: `pip install 'accelerate>=0.26.0'`
19:17: I commented-out the two device_map='auto' lines and now it seems to be downloading the weights. Now I just have to wait around 18 mins. But cool to see that they’re safetensors. That’s been one major safety and usability improvement to open deep learning models in the past couple years.
In the meantime, I asked gpt-4-turbo to re-write the boilerplate with mps compatability:
pbpaste | llm -s "Re-write this code to use the mps backend so it runs effectively on Apple Silicon." | tee /dev/tty | glow
That pastes from my clipboard as the prompt to the llm tool, then uses the system prompt (with the -s flag) for my instructions. I pipe the output to glow (a nice markdown rendered for the terminal) via /dev/tty which means I see the response stream in as plaintext so I can check it’s not doing something stupid before it finally gets sent to glow for pretty rendering.
The response wasn’t great, as it decided to also re-write half the code in a different way that seemingly has no bearing on mps support. But I’ll have to wait to find out if the key portion is correct. Honestly I could have just written the key bits myself, just add the line:
device = "mps" if torch.backends.mps.is_available() else "cpu"
and then .to(device) on the model.
Downloading model weights
19:34: I’m worried. Initially, the download progress bar seemed reasonable. It looked like 5GB file, which passed the sniff test for a 8B parameter model (with compression?), but I now see that that’s shard 1 of 7. Why would the model be so big? Overall that’s over 30GB.
Ohhh I see. Actually, that makes perfect sense for f32 weights: 8B x 32-bit (4-byte) floats is roughly 32GB. My 2x heuristic earlier was based on the assumption of f16 weights, which are commonly used for on-device LLMs. I should have read the small print. Also, it may not be trivial to do that conversion, but regardless I’m now limited by my download bandwidth and this won’t finish in time. Shit.
19:46: I was worried when I started on this earlier that downloading weights was going to be a bottleneck, but I handwaved away the 2-4x coefficient and didn’t expect so many delays on the road to actually getting a model downloading. Time to reassess.
Finding an alternative model
20:00: The OpenLLM Leaderboard on HuggingFace allows filtering by parameter size and reveals some interesting candidates in the 1–4B parameter range. I don’t have the time to look deeply into this now, but a small text-to-text model is something I might conceivably get running in the next hour.
20:05: Microsoft’s Phi-3.5-mini-instruct might do the job here. It’s 128k-context, 3.8B parameters in BF16, which is under 8GB to download. TIL, check the files section on HuggingFace to see the number and size of the .safetensor files beforehand.
20:22: It’s nearly finished downloading the first of the two safetensor files, so I’ve been using o1-preview to help me whip up a simple CLI (using rich and argparse) in the meanwhile that I can wrap around the LLM if/when it’s ready.
20:37: I got a nice CLI working (man, rich is such a great and easy library) that takes piped stdin and can pretty print or plaintext print to stdout. In the meanwhile, the download finished and the Phi test worked! But then I ran it again with macmon open and it’s running on the CPU? But that’s solvable, I think. It’s also complaining:
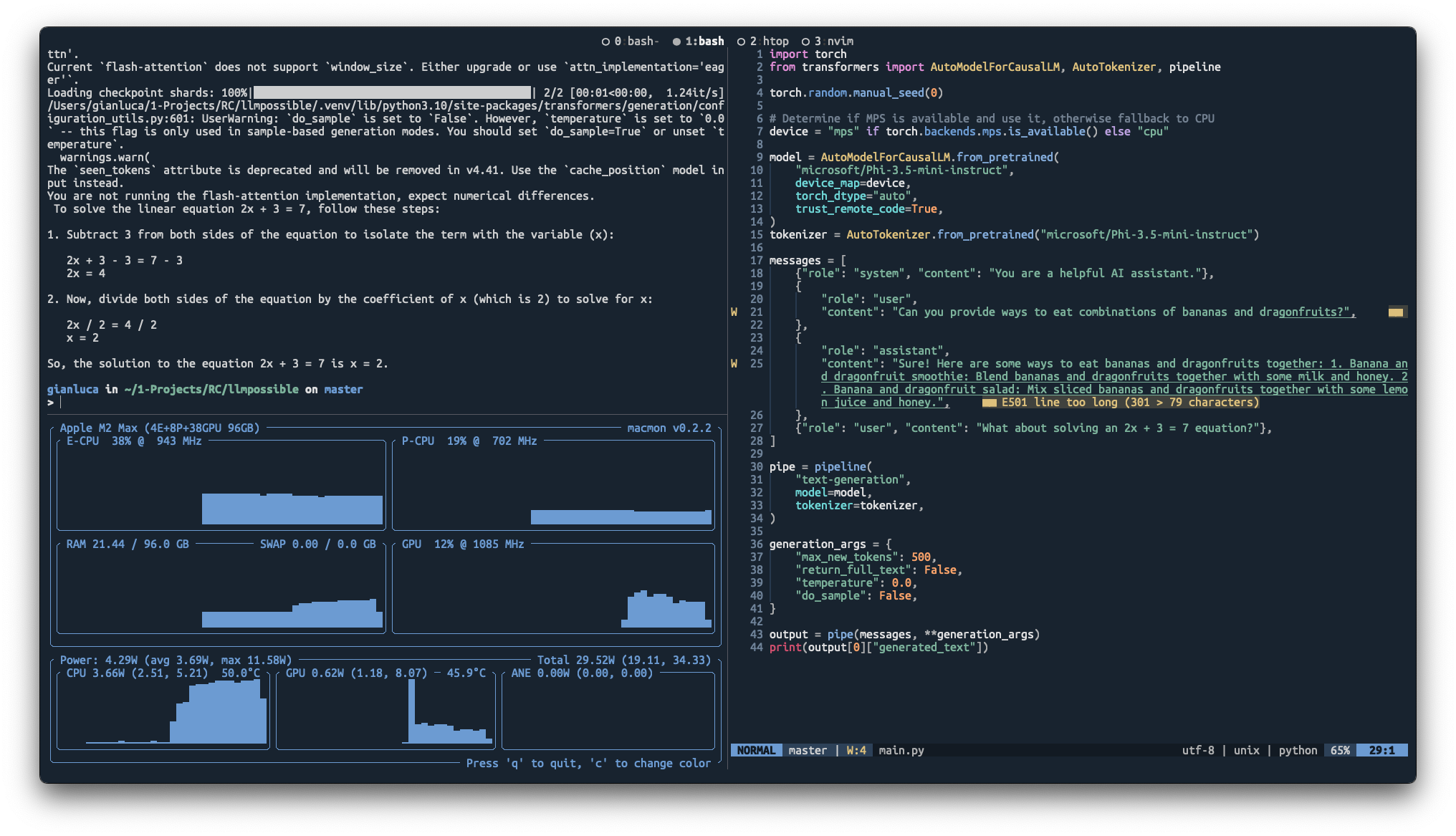
GPU acceleration with mps backend
20:47: I fiddled around a bit with adding to(device) where device='mps' and now it seems to be doing at least something on the GPU, but there’s still a massive CPU spike as well. The memory footprint also goes up by around 13GB, which checks out (2 x 8B estimate from earlier for 16-bit weights).
Naturally, I’m loading up and processing the model weights every time to run the single query. In an improved implementation, there would be a background process running when the model is likely to be needed, keeping the weights in memory and the model ready to go when the CLI process makes a request. A lot of the CPU hit and latency is probably from that. Not sure I’ll have time for that in the next 30 mins thought.
20:53: I’m going to try to evaluate that hypothesis by just running a bigger generation. That way, I’ll see a split between the load-setup phase and the generation phase of the LLM. (Ideally, I’d like to have the LLM stream it’s responses too. I’m going to do some digging into the transformers library to see if that’s reasonably easy to quickly implement.)
21:00: 30-minutes left of the official Impossible Stuff Day period. Whilst waiting on the LLM to spit out some stuff with my (and GPT-4-turbo’s) broken token streaming code, I looked into the flash attention warning and noticed on the HuggingFace page for Phi:
Note that by default, the Phi-3.5-mini-instruct model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types: NVIDIA A100, NVIDIA A6000, NVIDIA H100
This is a bit of a spanner in the works in terms of this being a good model in the long run. But whatever, I can switch models when I have overnight hours to download weights. The main goal was just to get this working at all.
21:07: Quick hack, I just manually forced device = 'cpu' and monitored what happened. Now there’s sky-high CPU usage, absolutely no GPU usage, and the whole thing is much much slower. So the mps was at least doing something. What’s peculiar is that there was seemingly no memory footprint on that run. Does that mean it was lazy-loading weights from storage? Surely not.
21:15: With a bit of fiddling, I have token-by-token output working. It starts off around 2 tokens per second (by my mental count), but then seems to slow to around 1 token per second. The memory footprint also creeps up and up. That would make sense, as nothing is getting collected or dumped from the process until the generation is complete and the script exits.
Running from a powerful and modular command line interface that supports UNIXy workflows
21:29: With little time to go, I did some context-powered prompt-yoloing with o1-preview and it actually worked! It was able to help me convert the LLM code into a simple async server daemon and update the CLI accordingly to use that as the source of queries. So now things stay in memory!
21:50: Just finished doing a 90-second demo to the rest of the Recursers who participated in Impossible Stuff Day. It worked!
Reflecting on 5 hours of attempting the impossible
At around 17:00, I had clarified the idea and broken it down into subgoals. Let’s review those as of 22:00.
I didn’t get a multi-modal model working, but that was mainly bottlenecked by privacy invasions and internet bandwidth. But I did get a capable 3B-parameter LLM (Phi-3.5-mini-instruct) running on my MacBook with GPU acceleration. I didn’t have time to do any fine-tuning or RLHF for subgoal 1b, but I have a great foundation to build on when I tackle that.
I also got everything wrapped up into a useable CLI tool that allows piping in and out (this means it would technically work from within vim too). It allows the user to toggle the rich text rendering with the --no-rich flag. That meets most of the criteria of subgoal 3.
- (1) A capable multi-modal LLM of at least 1B parameters running on my M2 MacBook
- (1a) GPU/ANE acceleration
- (1b) Fine-tuned/RLHFed to behave according to my preferences and goals
- (2) My personal data, previous work, and current projects as context
- (3) Running from a powerful and modular command line interface that supports UNIXy workflows
- piping to stdin and from stdout
- CL arguments
- config dotfile
- Vim integration
Overall, I’d call that a pretty good success. Despite taking the time to write this devlog as I went, wasting time trying to make use of Cursor, and burning over an hour finding an open LLM that didn’t want to harvest my organs or destroy my router, I managed to get the most important and foundational aspects of this “impossible” project completed.
This is huge! I’ve been meaning to revisit local models and dig deper on them for nearly a year now, but there was friction and analysis paralysis. The structure and accountability of Impossible Stuff Day was the nudge I needed. And I’m delighted that this attempt went so much better than the last one. I’m satisfied with today and looking forward to building on this work in coming weeks.
Notes on LLMs as levers
Earlier, in tactics for achieving the impossible, I reasoned that using LLMs for code generation would be a key lever to actually achieving “impossible” goals in only a few hours. The plan being to make use of Cursor and o1-preview to write boilerplate or cut down on the time required to utilise unfamiliar libraries. How did that hold up?
It was mixed. Cursor turned out to be a big time suck on set up (and sign up) and fiddling to figure out the changes since I last tried it and how to integrate it into my workflow.
Using o1-preview via the command line with llm turned out to be invaluable and probably saved me an hour of stressful integrations at the end by oneshotting a working daemon to serve the model to the CLI. I was impressed and relieved that that worked, but I’m not surprised. It probably cost $2 or $3 and I literally gave it this entire blog post and all my code and a detailed prompt as context:
llm --model o1-preview "You will help me write a finished piece of code. The following is my project plan:\n `cat ~/2-Areas/Blog/content/posts/rc-impossible-day-oct24/index.md` \n---\n And here is my code: `cat pyproject.toml main.py cli.py` \n---\n Write the integration between the local LLM model and the CLI. The model should be loaded (with mps) and stored in memory when a daemon process is started. Then the cli tool should merely invoke a generation. Also make any reasonable improvements and performance tweaks so this runs reliably and quickly on my M2 MacBook. "| tee ~/0-Inbox/impossible-o1-$(ecdt).md
If you’re using (neo)vim and are living on the command line, this is just a way more powerful and flexible and scrutable way to interact with these tools.
And being able to Perplexity search for quick answers (and then following the sources) massively cut down on the time required to pivot and change plans. It’s how I discovered the OpenLLM Leaderboard and thus a good fallback model.
These tools didn’t suppress my learning in this case. I know how to write basic CLI tools in Python and how to spin up a pair of processes in a client-server pair. But what I didn’t know was a lot of the tacit hands-on stuff about actually downloading SOTA LLMs from HuggingFace and spinning them up on a non-standard accelerator backend with transformers. And those things I was able to develop a knack for.
But you’d best believe I’ll be wading into the depths of the code myself now that the time pressure is off. Sprint, recover, assess, optimise, orient, repeat.
Next steps
There’s a lot I could do from here. These seem like the most pressing and interesting tasks to tackle next in this project:
- Figure out why the model actually seems to work fine despite the flash-attention warnings.
- Find a more appropriate base model (ideally multimodal and fully permissive) to build on.
- Dig deeper into the
mpssupport and perhaps look at writing bespoke mlx code to fully take advantage of the hardware (ANE + GPU). - Improve the daemon.
- Get response streaming to work and detokenize nicely.
- Implement LoRA finetuning.
You’re still here? Still reading this? Aww shucks!
Please reach out and tell me what you thought of this DevLog-style post and what I worked on. I’d love to hear from you, even if you just have scathing critiques.