
Open source code on Github: github.com/gianlucatruda/FOMO
After decades of being that abstruse thing PhD-wielding geniuses did in some wing of Google, “AI” finally arrived in every script kiddie’s toolbox overnight, right as the NFT shillers were migrating from crypto in search of new grifts.
And so since late 2022, keeping up with AI developments has become nearly impossible, particularly for people working in the field.
- Option 1, you spend all day refreshing twitter and pouring through newsletters. You don’t get any real work done, you’re anxious, an you still miss things that feel important because they were drowned out by hype.
- Option 2, you just keep your blinders on and ignore the important stuff along with the hype. You get more work done, but sometimes new advances make that work redundant overnight, and you fall further and further behind the cutting edge of topics you actually care about.
Okay, but why?
Since stable diffusion models took off in 2022, I’ve felt this was a problem of signal-to-noise ratio. Hype makes it easy to miss the important signal amidst the noise. As someone building an AI startup in the midst of that hype hurricane, I was feeling the problem acutely and decided there might be an Option 3.
I’d also been playing with embeddings since BERT and GPT-2 days. I still think embeddings are an often neglected, but insanely useful, feature of LLMs.
My co-founder and I had thrown around the idea of a “should I read this” app that leveraged the emerging text-parsing capabilities of LLMs to help trawl the overwhelming firehose of inbound information we were dealing with. Many months later, I came back to the idea and developed it into an MVP. It was a great series of two “sprints”, doing all the things YC and The Mum Test tell you to, along with improving my outdated front-end skillset.
Through user interviews, I distilled the problem down to the interplay between two feelings: one of missing out on that cool thing everyone’s talking about and one of feeling overwhelmed and demotivated by the quantity of shiny things demanding attention each day.
So I decided to codename the project FOMO1.
The goal was to see if LLMs could understand a user and their interests well enough to filter through all the new AI papers and projects, giving them a ranked stack of what to read. Bonus if it could also articulate why it was relevant to that specific user. Like the good old days of RSS, but with some GPT-powered personalisation.
How it works
Here’s an early system architecture sketch I did during the first sprint. Overall, it didn’t really change from this:
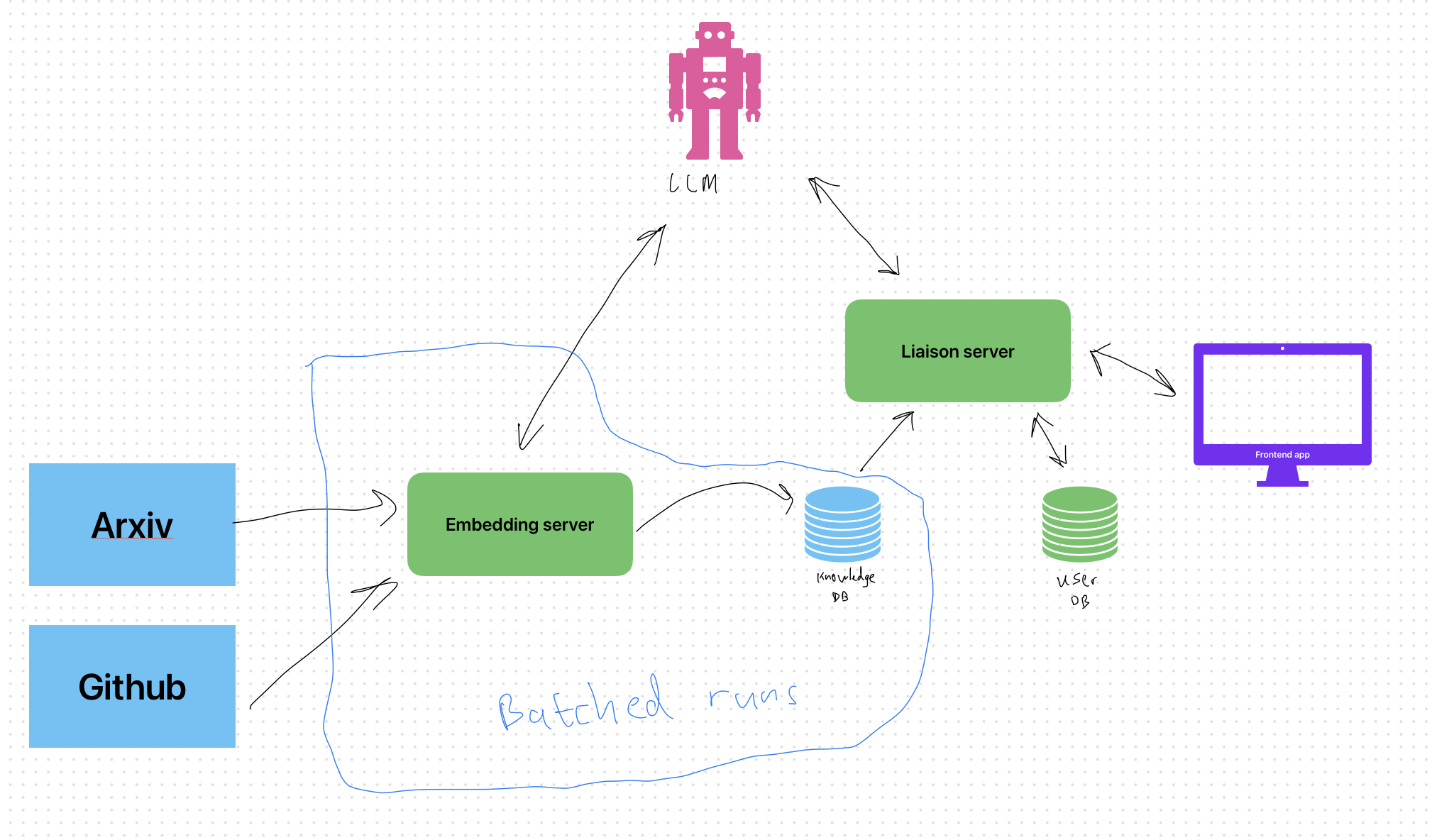
- Frontend: Next.js / React webapp (with tailwind.css styling)
- Backend: Python server (FastAPI, Uvicorn, Flask) that makes use of NumPy for fast in-memory embedding search.
I’m no longer actively working on this. If you want a great tool for semantic searching of arXiv papers, my good friend Tom Tumiel built arXiv Xplorer, which was part of the inspiration for this project.
that’s short for Fear of Missing Out, if you’re a boomer. ↩︎