2023 Update: This research is now complete. Read about the TableDiffusion model on my blog, see the full paper on arXiv, and the code on Github.
Abstract
Accessing sensitive data (like health records) is cumbersome because of ethical and regulatory restrictions. These restrictions help protect individual privacy, but impede research, particularly in biomedical domains. Dataset synthesis offers a potential solution.
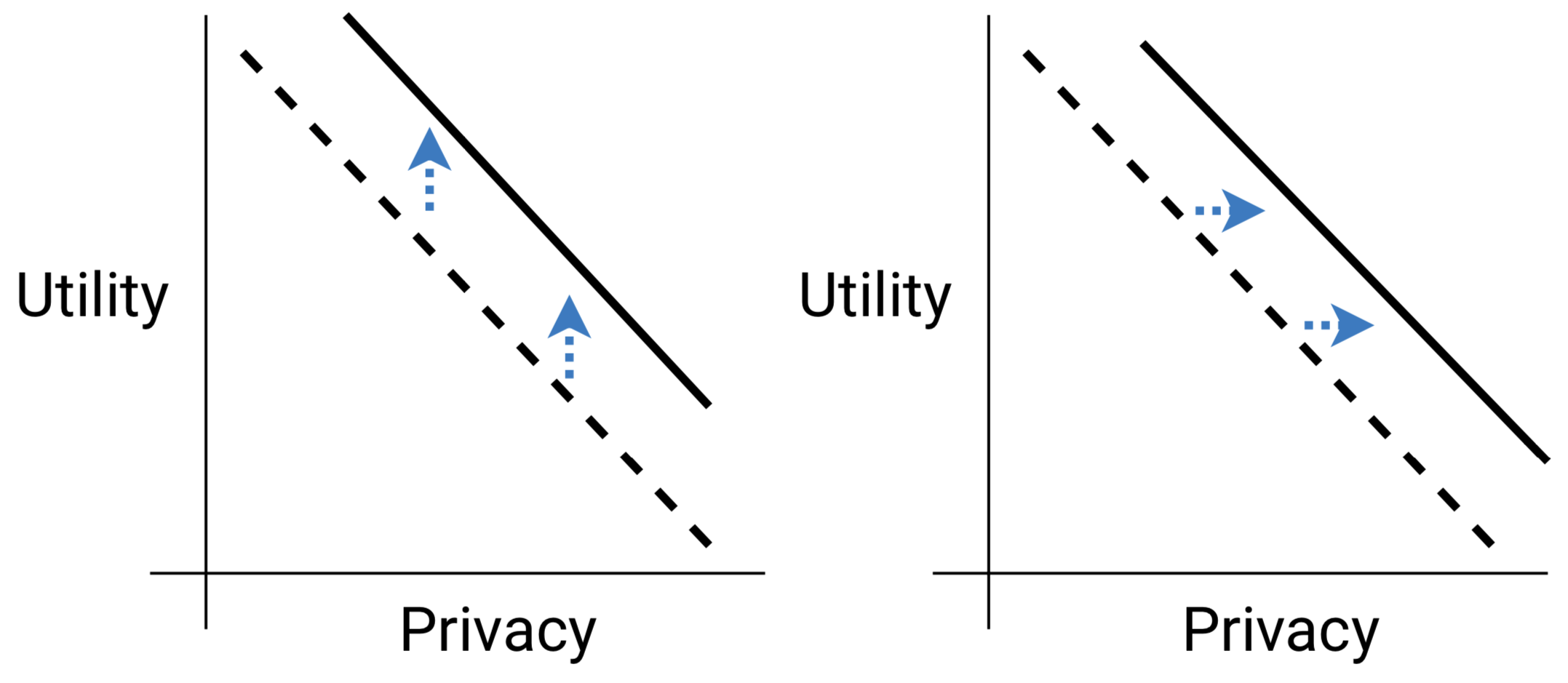
Generative adversarial networks (GANs) and variational autoencoders (VAEs) can synthesise new examples from the same probability distribution as their training dataset. Recently, researchers have produced synthetic datasets under strict differential privacy guarantees. However, there is a trade-off between the utility of the data and the privacy level.

This project aims to maximise the utility-privacy trade-off through
- Tighter privacy bound estimation
- Improved model implementations
Video explanation
Watch at this URL: youtube.com/embed/eW8fzOcpXAs
Introduction
Analysing data has yielded a wealth of knowledge in almost every industry over the past few decades. With recent advances in machine learning techniques and computing hardware, our capacity to extract valuable insight from raw data is only growing. Unfortunately, much of the most valuable data is sensitive and thus privately stored. The most notable examples are patient hospital records and other health data.
Accessing this sensitive data is inefficient and cumbersome because of the ethical and regulatory restrictions that have been imposed to protect individual privacy. It is expensive and complicated to install high-performance computing hardware on site and the regulatory hurdles are a major deterrent for researchers and companies to involve themselves with analysing the sensitive data. Moreover, institutions cannot benefit from pooling their data without risking security or legal violations. These restrictions on sensitive data help protect individual privacy, but create major impediments to scientific progress, particularly in biomedical domains.
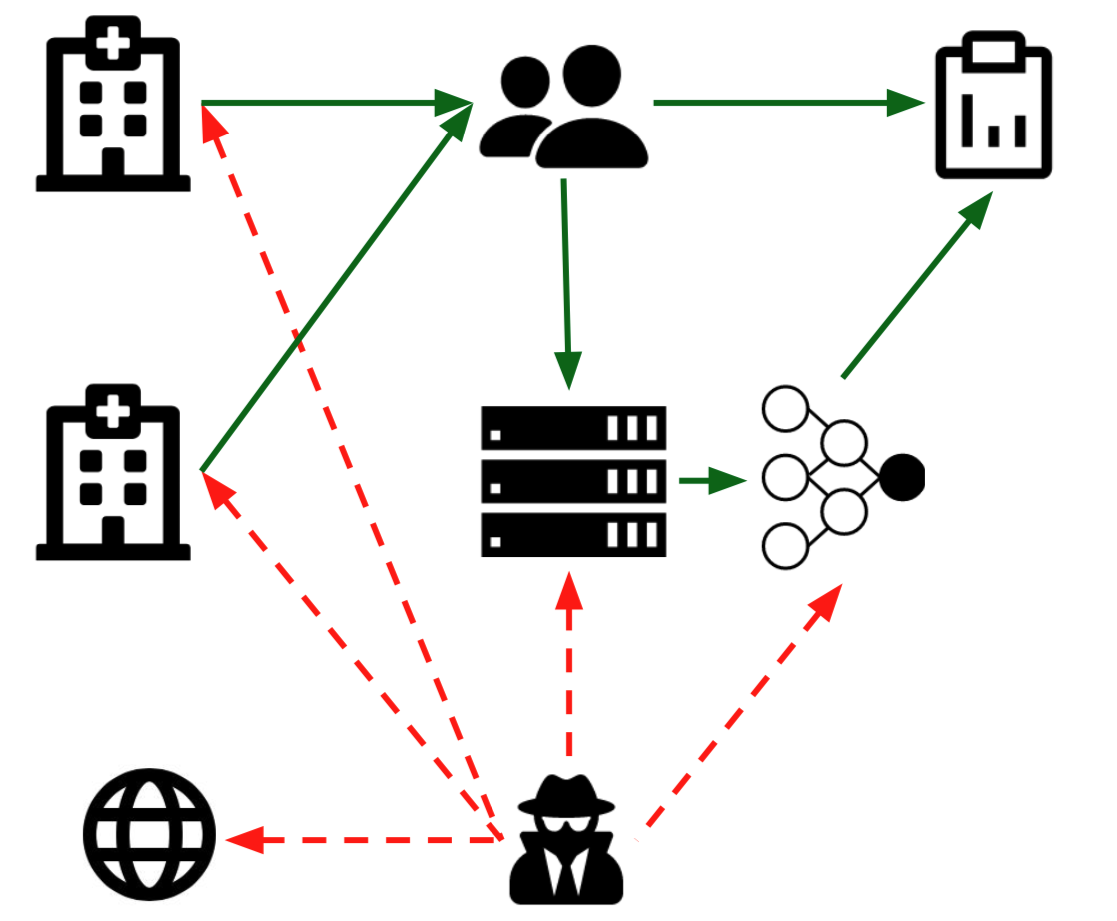
Ideally, it would be possible to interact with the data in a practical way whilst maintaining individual privacy. This goal is driving new lines of research in statistics, information theory, and machine learning. Dataset synthesis is one promising approach. Generative adversarial networks (GANs) and variational autoencoders (VAEs) can be used to synthesise new examples from the same probability distribution as their training dataset. This helps protect individual privacy, whilst maintaining group-level information.
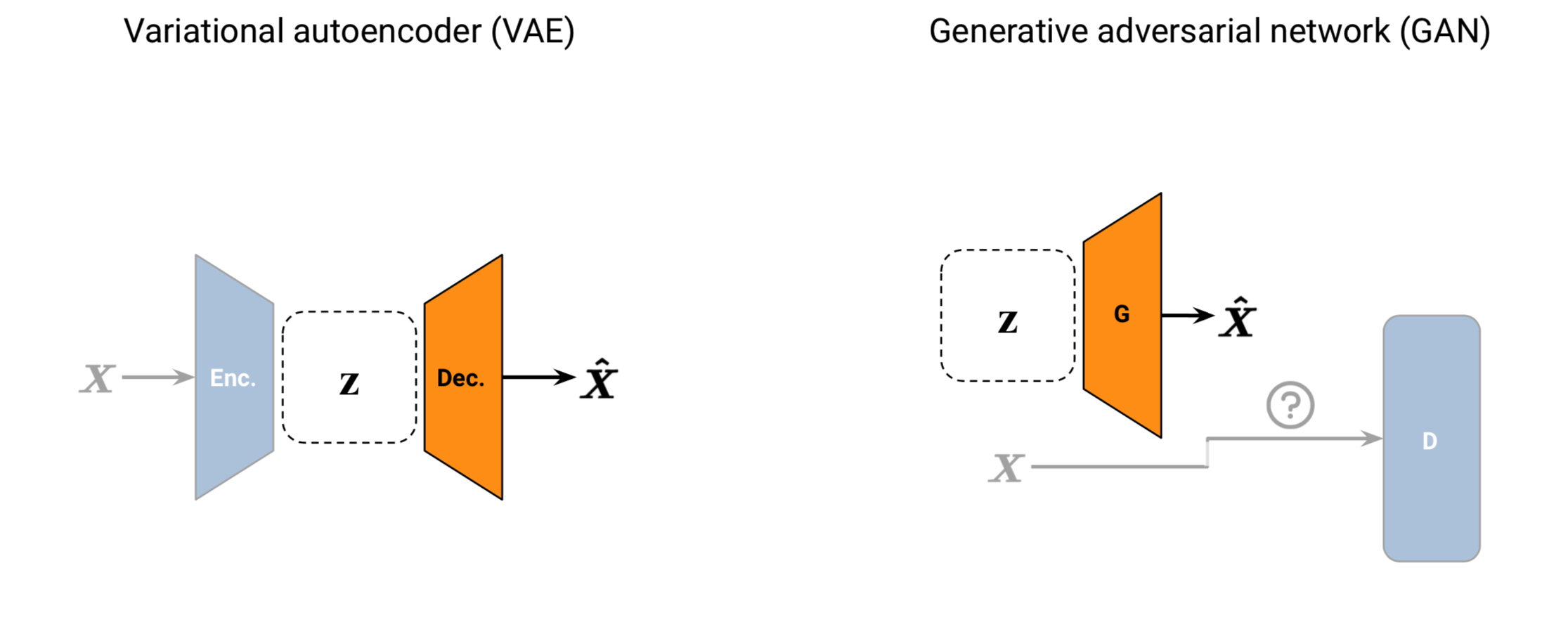
Unfortunately, there is a fundamental drawback to private machine learning: a trade-off between the utility and privacy of the synthesised data. Models that accurately fit the original dataset tend to regurgitate training samples, exposing sensitive data. Models that focus on privacy tend to synthesise examples that are not representative of the original dataset, which is not useful. There is also a large body of work demonstrating how these generative models can be attacked by malicious actors.
Fortunately, there are a number of ways to maximise the utility-privacy trade-off when synthesising data. Theoretical frameworks like differential privacy (DP) provide tools for making privacy guarantees, whilst advances in the efficiency and stability of deep generative modelling (like Wasserstein GANs) increase model quality.
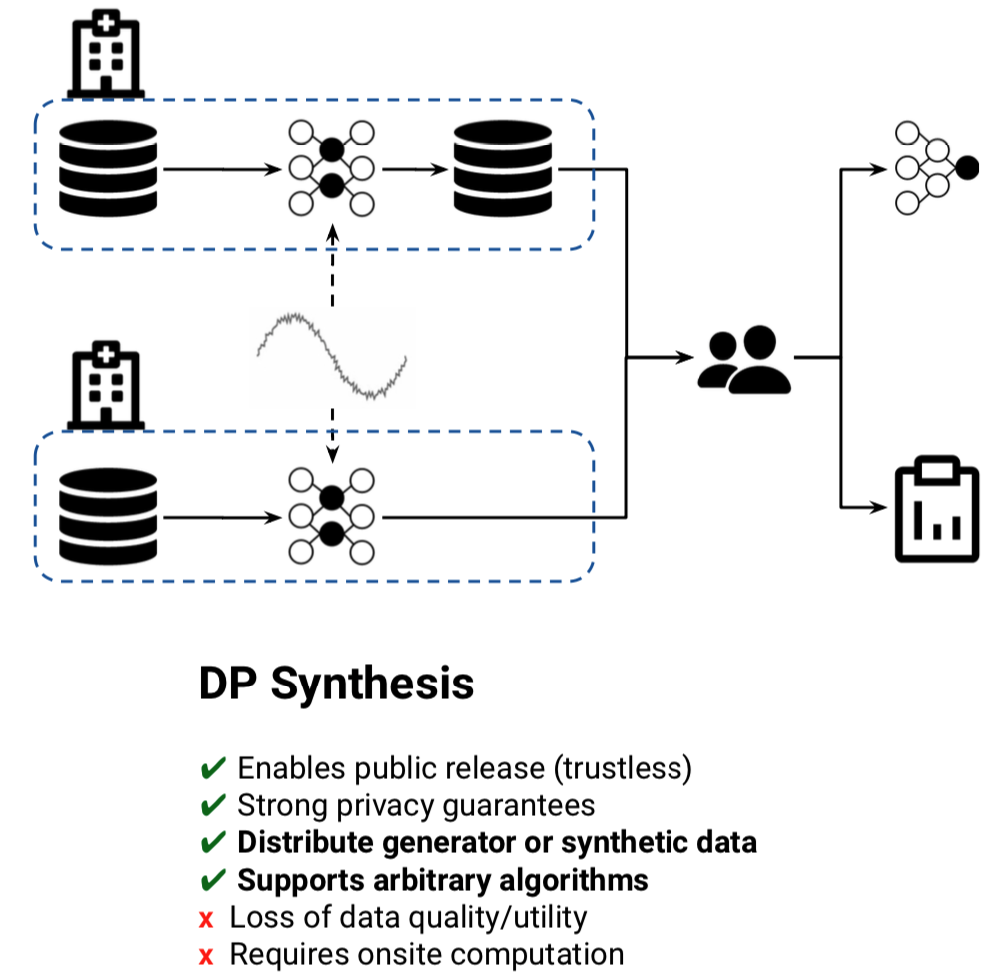
In the last 5 years, improvements in generative modelling and theoretical formulations of privacy have yielded promising results for data synthesis. It is has been shown that it is possible to produce synthetic datasets under the strictest privacy guarantees with only minimal loss in downstream prediction accuracy.
Understanding $(\epsilon, \delta)$-differential privacy
Differential privacy protects the confidentiality of individual respondents no matter what amount of external information may be available to an intruder—an attractive feature given the growing amount of information available on the internet which could be used for linkage and re-identification. — Charest et. al.
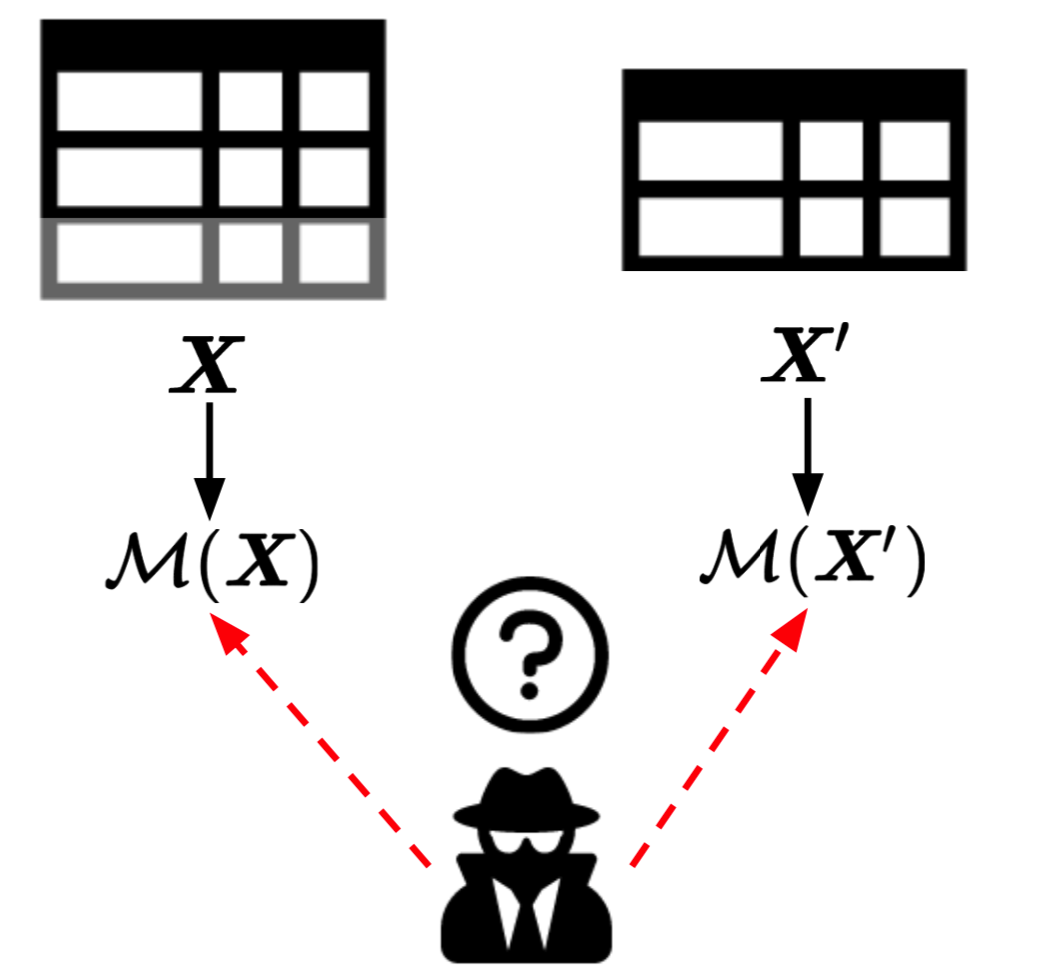
For $\epsilon, \delta > 0$, an algorithm $\mathcal{M}$ is $(\epsilon, \delta)$-differentially private if, for any pair of neighbouring databases $X, X'$, and any subset $S$ of possible outputs produced by $\mathcal{M}$,
$$ \operatorname{Pr}[\mathcal{M}(X) \in S] \leq e^{\epsilon} \cdot \operatorname{Pr}[\mathcal{M}(X') \in S] + \delta $$The constants $\epsilon$ and $\delta$ must be specified by the user. $\epsilon$ controls the level of confidentiality guaranteed by the randomised function $\mathcal{M}$. A smaller $\epsilon$ value implies stronger privacy guarantees. The constant $\delta$ is the probability that a single record is safe.
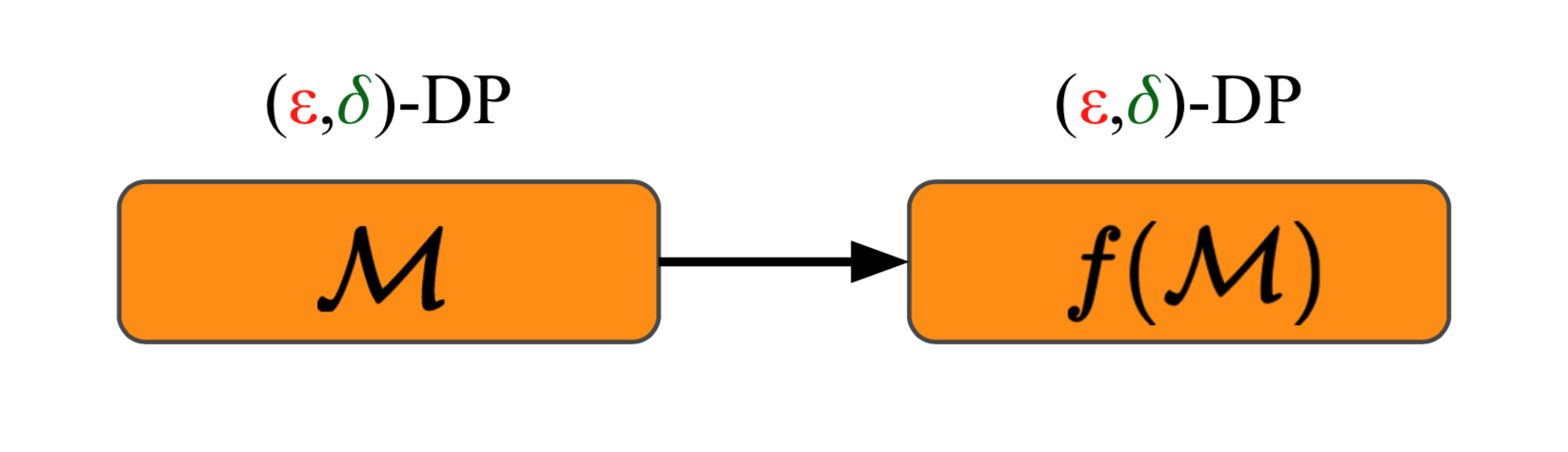
One of the superb guarantees made by differential privacy is the post-processing theorem: If we have an $(\epsilon, \delta)$-DP mechanism $\mathcal{M}$, then nothing we do to it will result in something that is not $(\epsilon, \delta)$-DP.
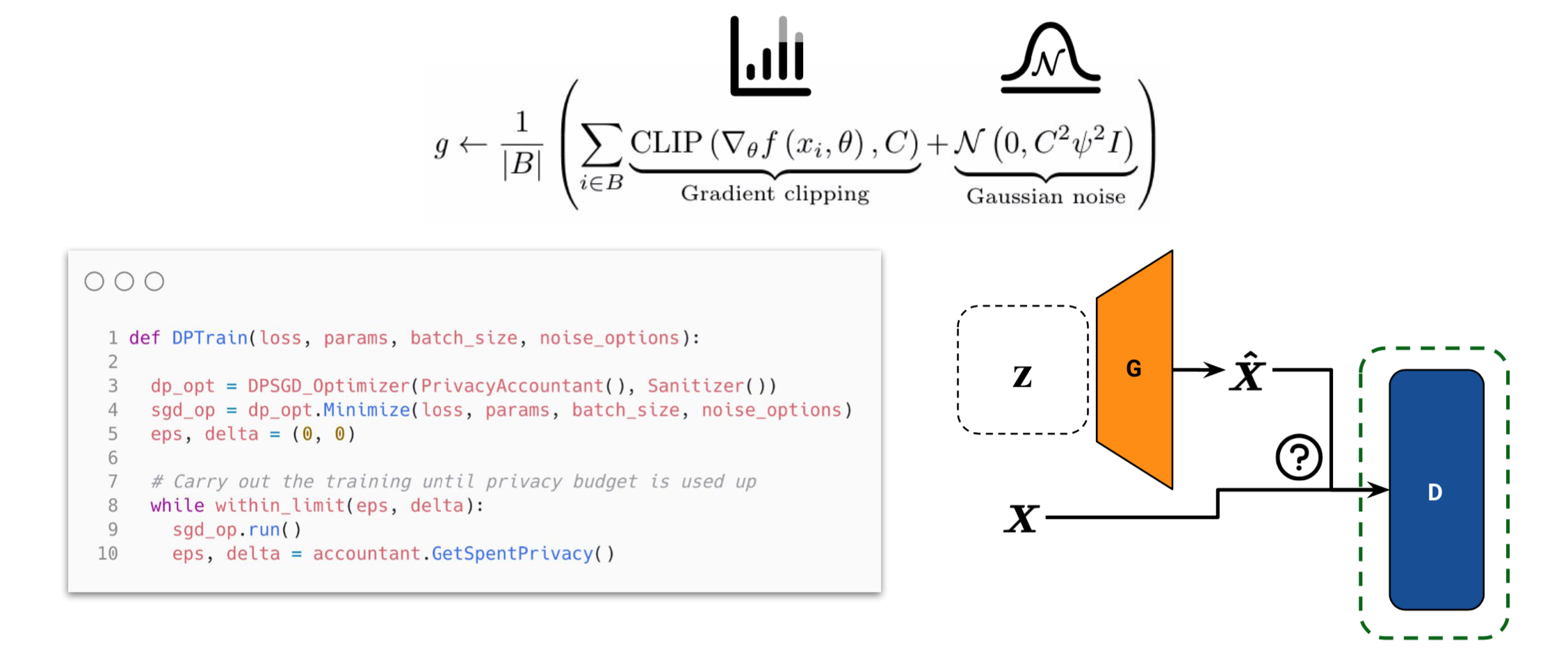
Differentially-private stochastic gradient descent (DP-SGD)
Problem statement
Improve the utility-privacy trade-off of generative models, with the goal of synthesising high-quality (medical) datasets that yield valuable insights about the original subjects without compromising individual privacy.
In other words: could we put the synthetic datasets on Kaggle and have anyone on the internet analyse/train on them without any risk (even in the long-term future) of the original subjects’ information being compromised? And would that Kaggle dataset produce any useful results?
Research questions
- More efficient privacy (RQ1): Can the same privacy budget be used for a greater number of computational steps and thus produce a higher-quality result?
- More efficient modelling (RQ2): Can we make generative models that produce the same dataset quality in fewer computational steps and thus using less privacy budget? quality and privacy?