I won’t recap all the public details about o1. They’ve been comprehensively surveyed and summarised by others.
Everyone agrees it’s a new paradigm, but nobody knows which one
Despite everything I’ve read in the days since OpenAI announced o1, I’m still unsure of so much.
In fact, the only two things I am sure about are:
- OpenAI is terrible at naming products
- there are no adults in charge 1
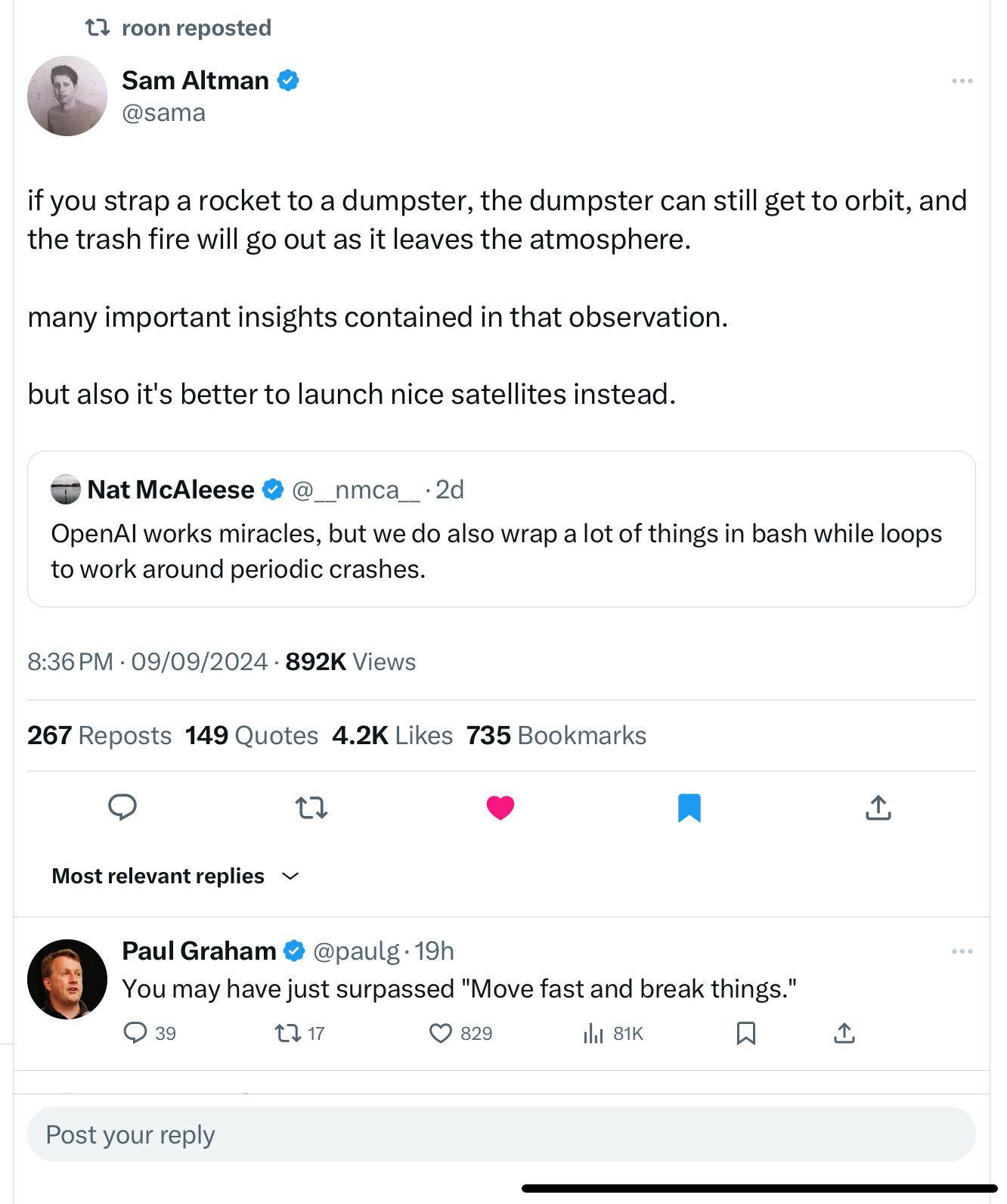
Where does this new approach fall on the spectrum of “just a model fine-tuned for spending a bunch of extra hidden tokens in a glorified version of thinking step-by-step” to “the full unification of the MuZero era of RL with multimodal LLMs”?
More specifically, the multi-billion dollar question: what exactly is o1 doing at inference time?
It seems like the most elucidating info is actually found in the API Docs, followed by the system (safety) card.
Not to be too much of an old man shaking his fist at the sky, but…
The “o” doesn’t stand for “open”
It’s deeply frustrating just how closed “OpenAI” has become — a trend at the frontier labs in general.
Even the technical reports are barely more than one long Abstract with none of the actual details (for obvious reasons). Other than the gratuitous evals porn, and some vague hints at “using RL,” they aren’t giving us much to go on.
“The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models”
Even the models are hiding things from us now:
“We believe that a hidden chain of thought presents a unique opportunity for monitoring models. Assuming it is faithful and legible, the hidden chain of thought allows us to “read the mind” of the model and understand its thought process. For example, in the future we may wish to monitor the chain of thought for signs of manipulating the user. However, for this to work the model must have freedom to express its thoughts in unaltered form, so we cannot train any policy compliance or user preferences onto the chain of thought. We also do not want to make an unaligned chain of thought directly visible to users.
Therefore, after weighing multiple factors including user experience, competitive advantage, and the option to pursue the chain of thought monitoring, we have decided not to show the raw chains of thought to users”
AI was more fun in the before times
As someone who was doing ML research back in 2018, where you could read the full methodology and entire codebase for new models, this is a frustratingly different world. One driven by hype trains, geopolitics, and ungodly levels of capital expenditure.
The closer you get to the “front lines” of this world, the more difficult it becomes to manage the psychological flip-flopping between existential panic and exhausted indifference.
You can easily fall down a Twitter rabbit hole or think about Yudkowsky’s earlier writing and have an “oh fuck” moment. Yet, at the same time, I work with frontier LLMs constantly and they’re still annoyingly bad at anything that truly matters.
Don’t get me wrong, you can have GPT-4 or Claude bootstrap a Bash script or web demo in minutes. You can build useful CLI tools in languages you don’t really know. You can summarise an entire book and ask specific follow-up questions. The activation energy required to achieve most knowledge-work has plummeted. In the hands of the savvy wielder, this is almost a silver bullet for getting shit done.
Yet, when it comes to the things that actually stump an expert, the LLMs collapse back to stochastic parrots and typically make the problem even worse 2.
And now there is so much capital and ego and nation-state weaponisation baked into this conversation that it’s nearly impossible to know where we’re at or where we’re headed.
And yet…
And yet, I’ve replaced 99% of web searches with asking an LLM via the terminal. And yet, I’ve replaced 70% of the remaining few web searches with Perplexity.
And yet, I’m personally exchanging close to a million tokens per day, interfacing with literal alien minds and doing so even more frequently than human ones.
We live in a strikingly different world to early 2022.
And yet…
It’s asymptotic
Everything has changed, but (even in tech) things are largely still the same. If you’re in the “AI bubble” you have no idea how different your perceived reality is from that of the people outside of it.
And so my hunch is that, in the limit, almost everyone overestimates short term impact and underestimates medium and long term impact.
This is an instantiation of an idea as old as technological progress.
It seems unimaginable that in 100 years we won’t be either extinct or have AGI gods running the show. And yet, simultaneously, I don’t want LLMs near any of my development pipelines for the foreseeable future.
To paraphrase William Gibson…
The future is already here — it’s just not temporally distributed
It’s fascinating to hear stories from the major generations of tech: EM/wireless, transistors, personal computing, internet, mobile. Those were all times of great change that we can look to for hints about our present one.
But there’s an aspect of existential threat in this technology that we haven’t grappled with since The Manhattan Project, and that shapes things differently.
I wrote Yesterday’s cutting edge is today’s table stakes back when GPT-4-vision got released and it felt like the whole world was about to catch alight.
And yet multi-modality seems to have faded in importance since then. Frontier LLMs have felt very much mundane for the past 6 months… until o1 was announced.
So, once more, we will use these things constantly and they’ll become an indispensable part of our workflows and our lives. But, at the same time, we’ll continue to be frustrated by their limits whilst worrying about what they might someday be capable of.
I think that pattern is going to play out recursively as we go forward. A fractally-shifting goalpost on the road to creating mundane gods.
That is, of course, unless the hype falters and the industry collapses and we find ourselves languishing in another AI winter. But with the number of GPUs Jensen has us burning, I’m not sure how that would cancel out.
To be fair, there never have been. Also, this is 90% just to show that tweet. I actually think that it’s entirely possible to be wrapping things in Bash while loops and entirely know what you’re doing. In fact, this may be peak productivity. ↩︎
To be fair, the same is true of many experts as well. ↩︎